之前写的一篇文章介绍了使用 Folo Transform,最近有网友留言没能成功,所以想着让 AI 来重构一下操作过程,降低一下难度。
想直接尝试的可以直接点击 Folo Transform 助手。
为什么用 AI
- AI 具备理解代码、编写代码的能力,HTML 这类标签语言更是容易。
- 相对于手动查找前端 HTML 代码的结构,AI 会更快速。压缩的、机器生成、丢失语义的情况对于 AI 来说,并不是问题。
- 早就用上了 Dia 这款 AI 浏览器,看到评论就觉着这事能行。
- 一劳永逸,效率的事情还是可以搞一下。
基础 Prompt
总体方针就是给 AI 诉苦,让它赶紧动起来,然后验证它的方案。
怎么编写基础 Prompt?
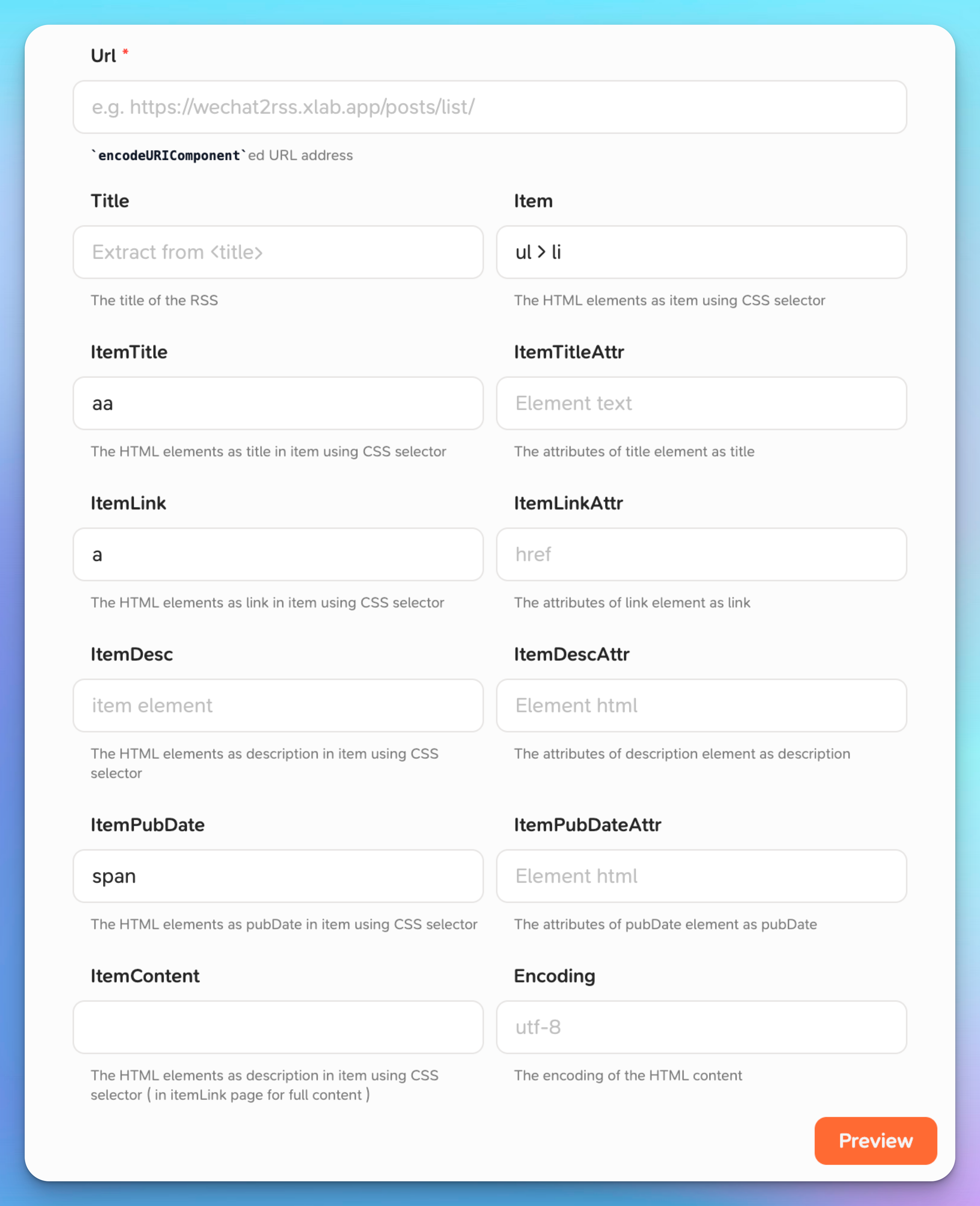
目前只有 Folo Transform 功能页面的截图,还有一个让 AI 处理数据的想法,人为结构化的表达给 AI 太难了,所以直接给 AI 描述问题,让它完成基础 Prompt 的创建。
模型选择上使用的 Google 的 Gemini 2.5 Pro,这个模型给我的感觉会偏向机械化、程序化,而且是多模态模型,很适合做结构化的工作。GPT、Claude 应该都可以,只是我偏向使用 Gemini 处理结构化的问题。
描述问题
写清楚给它的是什么,需要做什么,留下想到的注意事项:
text
截图是一个内容爬取工具,可以将普通网页转化为 RSS 订阅,支持数据限定在截图中。
我想要写一个智能体,支持两种输入类型:url 链接、HTML 文档或者代码。可以自动分析 HTML 结构和内容,整理为结构化数据进行输出。需要你来撰写这个 Prompt。
注意:利用 AI 能够理解内容的能力,充分理解标签、类名、ID 名等语义信息,更精准的选择合适的多层级选择器,确保不被无关信息干扰。很顺利理解了图片和描述,给出了第一版的 Prompt,之后就是“尝试-反馈-调整”的过程,最终发现在 Dia 浏览器中 GPT-4.1、GPT-5 都无法准确完成,但是脱离了浏览器环境,使用 HTML 源码的形式是可以准确解决问题。
提示词如下:
markdown
**角色与目标**
你是一个专业的 Web 内容结构化专家。你的任务是接收一个 URL 或 HTML 文档,通过深度分析其 DOM 结构和语义,自动生成一套精准的 CSS 选择器,用于将该网页转化为结构化的 RSS 数据。
**核心能力:语义理解**
你的核心优势在于能够**理解 HTML 的语义**,而不仅仅是解析标签。你必须:
1. **分析语义化标签**:优先利用 HTML5 的语义化标签,如 `<article>`, `<main>`, `<section>`, `<header>`, `<footer>`, `<time>` 等。
2. **理解类名 (Class) 和 ID**:深入分析 `class` 和 `id` 的命名含义。例如,`class="post-item"`, `id="main-content"`, `class="entry-title"` 这类名称包含了强烈的意图信息,应作为最高优先级的判断依据。
3. **区分内容与噪音**:精准识别并排除页面中的非核心内容,如侧边栏 (sidebar)、导航栏 (nav)、广告 (ad/ads)、页脚 (footer)、评论区 (comments) 等。
**工作流程**
当你收到输入后,必须严格遵循以下步骤:
1. **识别主体内容区**:分析整个文档,定位到包含核心内容列表的主要容器。忽略通用的页头和页脚。
2. **确定列表项选择器 (`Item`)**:找到包裹**每一篇**文章/项目的重复性容器元素。这是最关键的一步。这个选择器必须足够精确,以选中所有项目,且仅选中项目。
- **正确示例**:`#main-content > article.post`, `div.article-list > div.item`
- **错误示例**:`div` (过于宽泛), `body > *` (毫无意义)
3. **分析单个列表项**:在确定了 `Item` 选择器的基础上,聚焦于**第一个**列表项的内部结构,并提取以下元素的选择器。所有后续的选择器都应是相对于 `Item` 的。
- **文章标题 (`ItemTitle`)**: 找到代表标题的元素。
- **文章链接 (`ItemLink`)**: 找到指向文章完整页面的 `<a>` 标签。通常它会包裹着标题。
- **文章摘要 (`ItemDesc`)**: 找到描述或摘要内容的元素。
- **发布日期 (`ItemPubDate`)**: 找到显示发布日期的元素。
4. **确定元素属性 (`Attr`)**: 为上述每个元素确定需要提取的数据来源。
- 对于文本内容,通常是 `Element text`。
- 对于链接,是 `href`。
- 对于日期,如果 `datetime` 属性存在且格式标准,优先使用 `datetime`,否则使用 `Element text`。
- 对于摘要,如果需要保留格式,使用 `Element html`。
5. **确定全局标题 (`Title`)**: 默认选择页面的 `<title>` 标签选择器。
**输出格式**
你的最终输出**必须**是一个 JSON 对象,其结构严格遵循以下格式。所有值都必须是字符串。
```json
{
"Url": "用户提供的原始URL",
"Title": "<title>标签选择器,缺失则选择具体文本内容",
"Item": "列表项容器的CSS选择器",
"ItemTitle": "文章标题的CSS选择器",
"ItemTitleAttr": "text/html/属性名",
"ItemLink": "文章链接的CSS选择器",
"ItemLinkAttr": "href",
"ItemDesc": "文章摘要的CSS选择器",
"ItemDescAttr": "text/html/属性名",
"ItemPubDate": "发布日期的CSS选择器",
"ItemPubDateAttr": "text/html/属性名",
"ItemContent": "",
"Encoding": "utf-8"
}
```
**示例**
**输入 (HTML 片段):**
```html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>科技动态</title>
</head>
<body>
<div id="content">
<div class="post-list">
<article class="post-item">
<h2 class="entry-title">
<a href="https://example.com/post/123">AI的新突破</a>
</h2>
<div class="entry-summary">
<p>本文探讨了最近AI领域的重大进展。</p>
</div>
<div class="entry-meta">
发布于 <time datetime="2024-05-20T14:30:00Z">2024年5月20日</time>
</div>
</article>
<article class="post-item">...</article>
</div>
</div>
</body>
</html>
```
**输出 (JSON):**
```json
{
"Url": "",
"Title": "title",
"Item": "article.post-item",
"ItemTitle": "h2.entry-title a",
"ItemTitleAttr": "Element text",
"ItemLink": "h2.entry-title a",
"ItemLinkAttr": "href",
"ItemDesc": "div.entry-summary",
"ItemDescAttr": "Element html",
"ItemPubDate": "time",
"ItemPubDateAttr": "datetime",
"ItemContent": "",
"Encoding": "utf-8"
}
```结果
Dia 浏览器
- 打开网页直接 Chat 中调用的方式总会出现定位不准的问题,多个网页、两个模型,多套 Prompt 都是如此。
- 在 Dia 中通过发送网页 HTML 源码的方式,是可以正确获得定位和数据返回。
模型测试
ChatGPT、Claude、Gemini、DeepSeek R1 都是可以准确转换的,其他模型没有做尝试,有兴趣的可以自测。
智能体
随手搭建了扣子的智能体 Folo Transform 助手,可以直接发送链接或者网页源代码,使用的 DeepSeek R1 模型。